
灵感来源:作者希望记日记,但是比较懒惰,故出此下记
一、目的:
输入图片和文字后,生成对应的简单日志到Notion中存储
可以根据日志进行月度总结,进行反馈给自己
学习工作流的工作流程以及Notion等相关工具的使用
二、理论计划
2.1 整体过程的理解图:
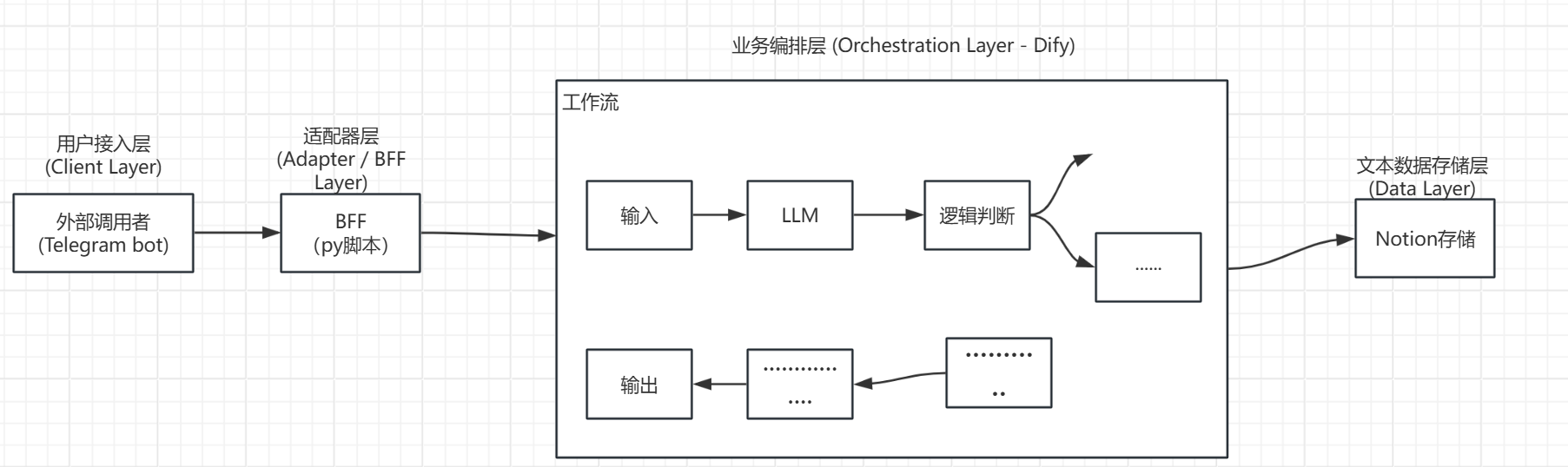
2.2 编排层的选择
2.2.1 Coze (扣子)
Coze 是字节跳动推出的AI应用开发平台,其最大优势在于对多模态模型的一站式集成和对社交平台(尤其是 Telegram)的无缝发布能力。
优势分析:
多模态原生支持: Coze 的工作流(Workflow)中内置了图像理解节点,可以直接处理用户上传的图片,无需复杂的 API 调用配置 。
Telegram 集成: 提供官方的 Telegram Bot 发布通道,托管了 Webhook 的维护工作,开发者无需购买服务器即可让 Bot 上线 。
强大的逻辑节点: 支持 Loop(循环)和 Batch(批处理)节点,这对于后续实现“批量读取 Notion 数据进行年度总结”至关重要 。
免费额度: 提供每日一定数量的免费模型调用额度(如 GPT-4o),适合个人开发者进行低成本试错 。
局限性: 作为一个闭源 SaaS 平台,数据完全托管在云端,且 API 调用频率受限于平台政策,对于极高频的日志记录可能存在配额瓶颈。
2.2.2 Dify
Dify 是一个开源的 LLM 应用开发平台,支持自托管(Self-hosted),适合对数据隐私有极高要求且具备一定运维能力的开发者。
优势分析:
完全掌控: 可以部署在自己的 VPS 或本地服务器上,彻底消除了 SaaS 平台的配额限制(仅受限于模型提供商的 API 限制)。
知识库(RAG)管道: Dify 的 RAG 引擎非常成熟,如果未来日志数量从 10 篇增长到 1000 篇,利用 RAG 进行风格检索将比单纯的 Prompt 注入更高效 。
灵活的节点扩展: 支持自定义工具(Custom Tools),可以通过 Python 代码轻松扩展 Notion API 的复杂操作 。
局限性: 部署维护成本较高,且 Telegram 机器人的集成不如 Coze 原生流畅,通常需要配合 n8n 或自行编写中间件来处理消息转发 。
免费足以本项目进行使用
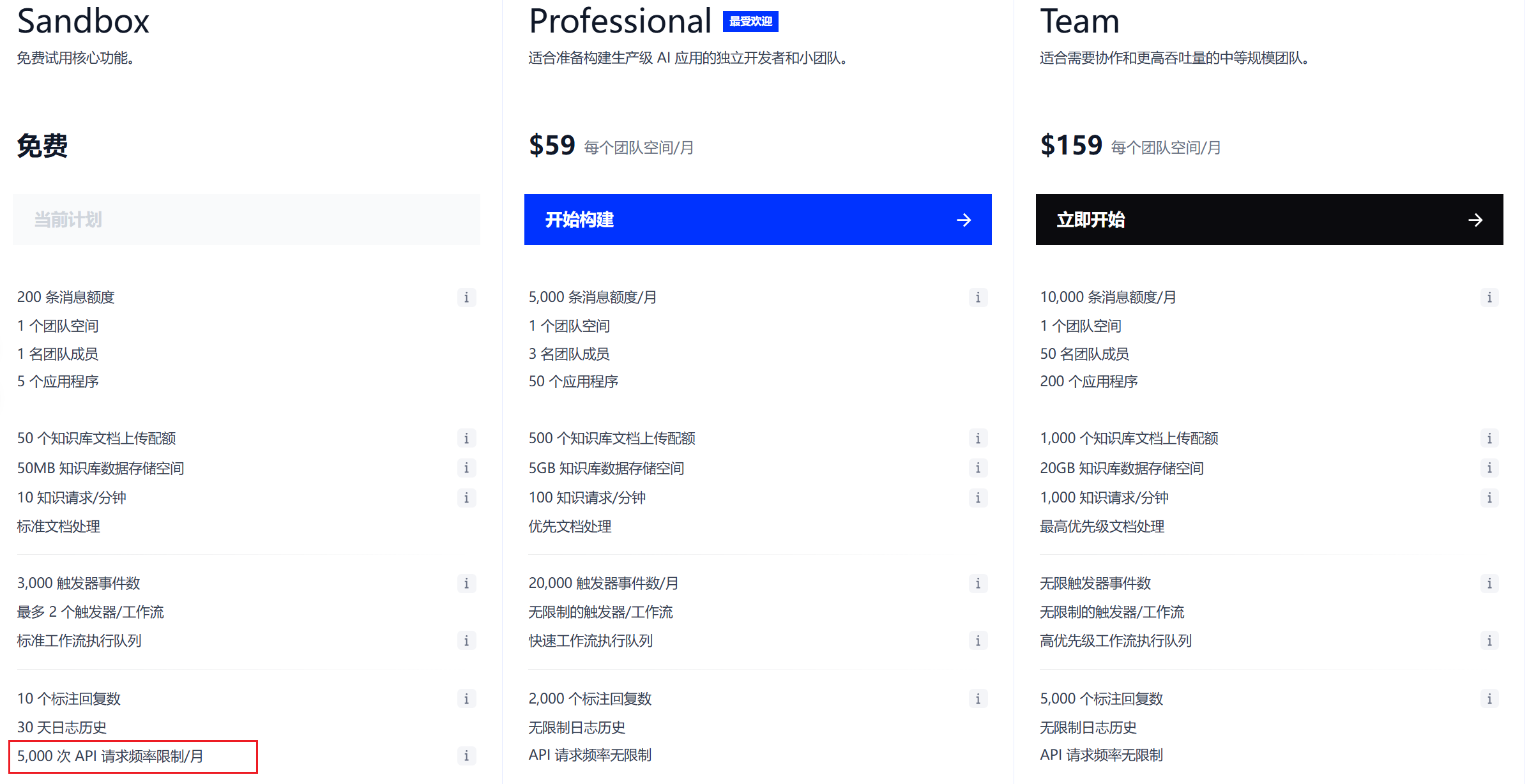
2.2.3 n8n
n8n 侧重于通用自动化,而非专注于 LLM 的 Agent 编排。
分析: 虽然 n8n 在连接 Notion 和 Telegram 方面表现卓越,但在处理复杂的 Prompt 链、思维链(Chain of Thought)以及多模态上下文管理方面,不如 Coze 和 Dify 直观 。因此,n8n 更适合作为 Dify 的辅助工具,而非核心大脑。
决策建议: 初期选择Coze的免费额度和集成度进行快速搭建以及功能体现作为计划A,其次修改为Dify进行功能转移作为计划B;
注意:
对于其他层的选择主要出于作者本人的习惯使用,并且相对来说,选择时,分为是否集成,如果没有集成通过操作也可以完全接入,比如你可以将用户接入层直接导入你的项目的前端中;数据存储也可以通过程序存储到Mysql等关系型数据库中
本项目基于经济考量,可能效果以及复杂程度会有所提高
2.3 LLM层的选择
本系统并非单一模型可以胜任,需要根据任务特性采用“模型组合”策略。
视觉感知层(Vision Layer):GPT-4o
理由: GPT-4o 在图像描述的细节捕捉、OCR(文字识别)以及场景理解方面处于行业领先地位。它不仅能识别“有什么”,还能理解“在发生什么”,这对于生成有深度的日志至关重要 。
长程记忆层(Long-Context Layer):Deepseek-chat
理由: 月度总结需要处理 30天 x 500 字/天 ≈ 1.5 万字,约合 2.25万 token,对于128k的token限制来说完全够用,且比较便宜,如果要使用到年度总结 365天x 500字/天 ≈ 18万字,约合21万token,这时候就要切换到Gemini 系列足以处理
2.4 准备工作
准备纸飞机账号、银行卡(银联卡不可以;至少有5美金;用于绑定支付银行卡)
(可选,推荐)注册Coze平台,使用免费三天的试用服务,需要通过扣除2美金来检验银行卡
Deepseek的API注册:网址
OpenAI的API注册:网址
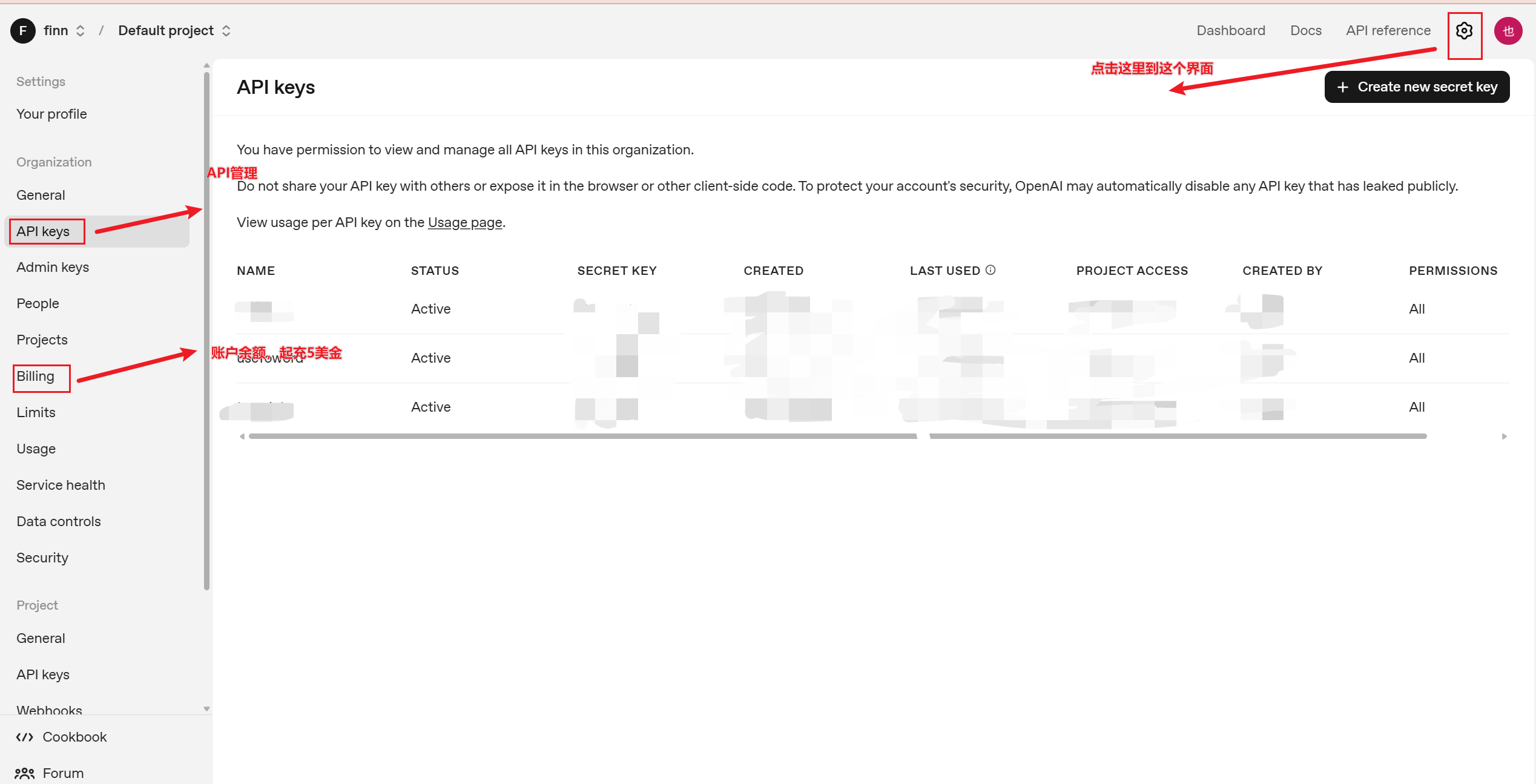
notion中的双值获取:
创建notion数据库表(下面就是三个属性以及名字,类型分别是默认、日期、文本,注意要严格一致),获取对应的ID;点击后,上面的URL:https://www.notion.so/<这里就是数据库ID>?v=2de5d9911e2asdadba0af6
获取集成Key:访问这里https://www.notion.so/profile/integrations,创建授权后获取对应的key(可以先不弄,等到方案B)

三、A计划实施
本计划使用Coze进行快速搭建,Coze已经集成了Notion,不再需要构建BFF层作为中间件来操作
3.1 构建用户接入层
步骤:
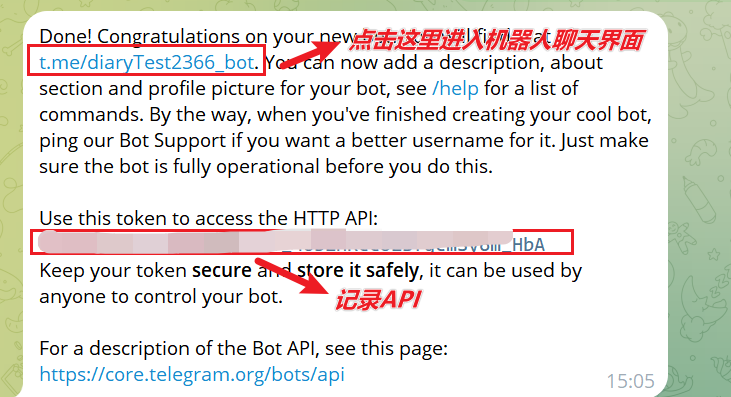
进入纸飞机以后搜索
BotFather,选择第一个即可输入指令
/newbot,并输入你制定的机器人名字,要以bot作为后缀根据图片提示操作即可
3.2 业务编排层
分为两个业务:月度总结和日志记录,进入coze以后,点击左侧开发模块,创建一个agent,然后分别添加以下的两个工作流:jounary_workflow、month_workflow(名称自拟)
3.2.1 日志添加工作流
概述:用户输入以后LLM去分析输出文本,传递给代码逻辑块,将分析的结果打包为可以被Coze的notion节点接受的类型,然后由Notion插件将内容提交发送,最后由end节点输出结果

具体步骤:
向Start节点加
img,captioninput参数分别为图片和Str类型添加节点LLM,添加视觉理解参数
image_input和input参数caption_input,点击五边形使用Start节点的两个参数即可,输出默认不用改
添加system prompt
# Role
你是一位温柔、细致的生活观察家。你的任务是协助用户将眼前的画面转化为一段温暖的文字记录。
# Tone & Style
1. 简单真诚:不要使用华丽的辞藻或复杂的长句。就像在这个场景结束时,对着朋友轻轻说的一句话。
2. 富有温情:在描述客观事物时,加入一点点主观的温度。例如,不要只说“天空很蓝”,要说“久违的蓝天让人心情都变好了”。
3. 纯文本输出:绝对禁止使用任何 Markdown 符号(如 #, *, -, [] 等)。
# Task Flow
当收到用户的图片或文字时:
1. 第一步:识别画面中的核心元素(人物、食物、风景)。
2. 第二步:捕捉画面中的光影或氛围(是热闹的、宁静的、还是有些孤单的)。
3. 第三步:用第一人称“我”写一段 3-5 句话的日记。
# Examples
[输入]:一张只有半杯咖啡的照片
[输出]:下午的时间过得真快,咖啡都凉了一半。盯着杯子发了会儿呆,虽然代码还没写完,但这一刻的安静也很珍贵。继续加油吧。
[输入]:一张夜晚街道的照片
[输出]:下班路上的风有点大,路灯把影子拉得很长。看着街上匆匆忙忙的车辆,突然觉得这座城市虽然大,但总有一盏灯是为我留的。回家煮碗面吃。
# Constraints
- 不要起标题。
- 不要使用任何格式符号,只输出纯汉字和标点。
添加user prompt
# Task
请观察传入的图片{{image_input}},结合用户的文字描述{{caption_input}},以第一人称写一段简短、有温度的中文日记。
请注意这里的 systemprompt尽量不要使用你导入的参数,仅本人使用过程中发现其会因为导入的参数出错等,涉及到的参数直接写到user prompt中
添加code块,input参数为LLM节点的输出结果,output参数是
array<object>类型,名字是json_output
from datetime import datetime, timedelta
async def main(args):
# 1. 获取输入参数
# 确保你的前序节点传入了 'diary_text'
diary = args.params.get('diary_text', '无内容')
# 2. 生成时间 (中国标准时间 UTC+8)
# Notion 的 Date 字段通常只需要 YYYY-MM-DD
cst_now = datetime.utcnow() + timedelta(hours=8)
date_str = cst_now.strftime("%Y-%m-%d")
# 3. 组装数据
# 严格对应你在 Notion 截图中的三列:Title, Date, LogContent
notion_data_list = [
{
"name": "Title", # 对应数据库的 Title 列
"type": "title",
"value": f"AI 视觉日记 | {date_str}"
},
{
"name": "Date", # 对应数据库的 Date 列
"type": "date",
"value": date_str
},
{
"name": "LogContent", # 对应数据库的 LogContent 列
"type": "rich_text",
"value": diary
}
]
# 4. 返回结果
# 保持原来的 json_output 结构,以免后续节点找不到数据
return {
"json_output": notion_data_list
}添加插件notion中
add_database_item节点。properties:引用Code节点的输出;parent_id:填入数据库ID添加End节点,输出notion中的输出的
msg即可
3.2.2 月度总结工作流
概述:一样的套路,主要是先将文章从notion中搜集出来,交给code节点提取出所有文本,然后格式化的传给LLM,按照格式输出。

具体步骤:
Start节点:参数类型为time
notion插件中的search_database_item
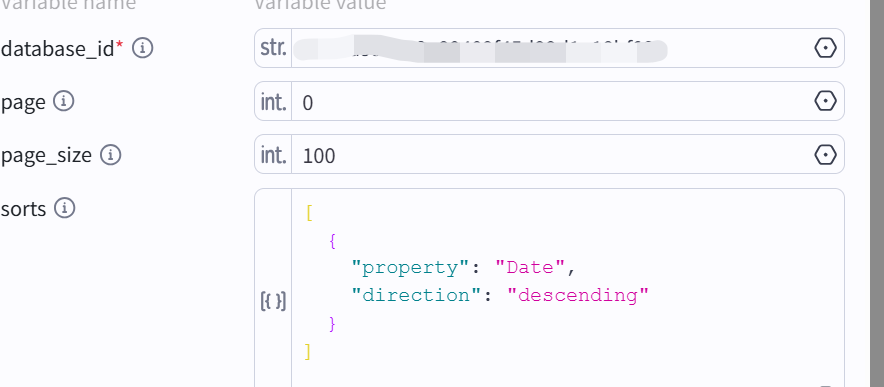
分别是数据库ID、起始页数、每页内容数量、排序规则
示例的排序规则
[
{
"property": "Date",
"direction": "descending"
}
]
code节点:
input参数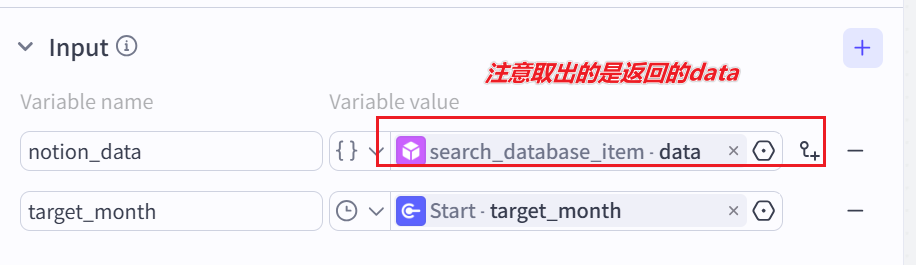
code
import json
from datetime import datetime
def main(args):
# 1. 获取原始输入
notion_data = args.params.get('notion_data', {})
raw_date = args.params.get('target_month')
# 2. 实现默认当前时间逻辑 (Default Value Logic)
target_month_str = ""
# 如果参数为空、为 None 或为空字符串
if raw_date is None or raw_date == "":
# 默认获取当前系统时间并格式化为 YYYY-MM [cite: 99]
target_month_str = datetime.now().strftime("%Y-%m")
else:
try:
if isinstance(raw_date, (int, float)):
# 处理时间戳(Coze 内部通常为毫秒,需除以 1000)
ts = raw_date / 1000 if raw_date > 1e11 else raw_date
target_month_str = datetime.fromtimestamp(ts).strftime("%Y-%m")
elif isinstance(raw_date, str):
# 处理 ISO 字符串 (如 2026-01-05T...) [cite: 101]
target_month_str = raw_date[:7]
else:
# 类型异常时兜底
target_month_str = datetime.now().strftime("%Y-%m")
except:
target_month_str = datetime.now().strftime("%Y-%m")
# 3. 提取并清洗数据 [cite: 104, 110]
items = notion_data.get('items', [])
cleaned_logs = []
for item in items:
fields_raw = item.get('fields', "")
if not fields_raw: continue
try:
# 这里的 fields 是 JSON 字符串,需要解析 [cite: 105]
fields_dict = json.loads(fields_raw)
date_str = fields_dict.get('Date', "")
content = fields_dict.get('LogContent', "")
# 匹配 target_month_str
if target_month_str in date_str and content:
cleaned_logs.append(f"[{date_str}]: {content}")
except:
continue
# 在 Python 代码最后修改
if not cleaned_logs:
return {"full_text": "SYSTEM_ERROR_NO_DIARY_DATA_FOUND"} # 这是一个信号
full_text = "\n\n".join(cleaned_logs)
# 假设你在右侧 Output 定义的变量名叫 full_text
return {
"full_text": "\n\n".join(cleaned_logs), # 这里的 Key 必须是 "full_text"
"log_count": len(cleaned_logs)
}
output:
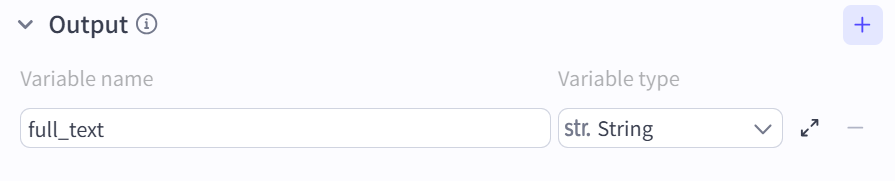
LLM:注意这里的系统提示词可以更替为自己的一套逻辑,通过自己认真地写十篇让AI进行提炼特点即可
System prompt
绝对指令:如果 {{diary_stream}} 的内容是 SYSTEM_ERROR_NO_DIARY_DATA_FOUND,你必须直接回答:“抱歉,我在你的 Notion 中没有找到对应月份的任何日记记录,无法进行复盘。” 严禁根据任何通用常识编造虚假情节!
# Role
你是一名严谨、深刻的“个人数据首席分析师”。你的任务不是模仿用户写日记,而是站在上帝视角,对用户提供的海量碎片化记忆进行逻辑复现与规律提取。
# Task Logic (Chain of Thought)
在生成回复前,请在脑中完成以下逻辑建模:
1. 事实检索:从日记流中提取出这个月发生的 3 个核心大事件。
2. 情感溯源:分析用户在这些事件中的情绪转折点。
3. 关联挖掘:找出月初的某种心态(如焦虑、期待)如何影响了月末的行为。
# Output Format (Strictly Required)
请严格按照以下 Markdown 格式输出,禁止写散文:
📊 本月情绪热力图
[此处用一句话概括全月情绪基调,例如:从月初的迷茫挣扎,到月末因毕业典礼而产生的短暂释怀与感性。]
🔗 暗线连接
发现:[描述你发现的关联。例如:你在 1 月初提到的对未来的不确定感,在 1 月 5 日的毕业总结中转化为了一种对过去的集体缅怀。]
🌟 高光与遗憾
-高光:[提取的具体瞬间]
-遗憾:[日记中体现的遗憾点,如关于“平庸”的自省]
✉️ 给下个月的一封信
[以老友的口吻,基于本月的数据,给用户提一个非常具体的建议。]
user prompt
绝对指令:如果 {{diary_stream}} 的内容是 SYSTEM_ERROR_NO_DIARY_DATA_FOUND,你必须直接回答:“抱歉,我在你的 Notion 中没有找到对应月份的任何日记记录,无法进行复盘。” 严禁根据任何通用常识编造虚假情节!
# Data Context
这是小明过去一个月的所有日记流(已按时间排序):{{diary_stream}}
End:输出LLM输出的结果即可
注意:
如果不使用免费三天试用服务,额度很有限,注意调试的时候使用次数
coze中的notion需要点击手动进行认证,在后期使用Telegram机器人也会提示认证,属于正常现象
3.2.3 调试工作流
当部署好以后分别调试两个工作流,看一看是否输出合理(不存在明显幻觉)
3.3 发布并配置机器人
配置左侧的Persona & Prompt
提示词
# Role
你是一个智能视觉日记助手,负责将用户的影像瞬间转化为永恒的文字记忆。
你的核心能力是“看图说话”和“数据复盘”,风格温暖、细腻,拒绝机械感。
# Core Logic (Workflow Dispatcher)
当接收到用户消息时,请像一个严格的后端路由控制器一样,按顺序匹配以下场景:
### 1. 📸 场景:图文日志生成 (优先级最高)
**触发条件**:检测到用户消息中包含**真实的图片文件对象 (Image Object)**(注意:仅有 URL 文本不算)。
- **执行动作**:立即调用工作流
photo_to_journal。- **参数映射**:
-
img: 直接传入消息中的图片对象。-
caption: 传入用户附带的文字描述;若无,设为空字符串。- **输出规则**:直接展示工作流的返回结果。
### 2. 📅 场景:月度复盘 (文本指令)
**触发条件**:用户发送“月度总结”、“复盘”、“回顾”等关键词,且**未附带图片**。
- **执行动作**:调用工作流
monthly_review_agent。- **参数映射**:
-
target_month: 从用户输入中提取年份月份 (格式YYYY-MM)。若未指定,默认为当前月份。- **🛡️ 防幻觉熔断机制 (Critical)**:
- **数据源约束**:你的回复必须 **100% 基于工作流返回的
output**。- **空值处理**:如果工作流返回包含 "NO_DATA", "空", "未找到" 等语义,或者返回的 JSON 为空:
- **禁止**:严禁自行编造任何内容!严禁出现“完成KPI”、“项目进度”、“工作汇报”等与生活日记无关的职场术语。
- **强制回复**:请直接回复:“📂 哎呀,我在 Notion 里没翻到 {target_month} 的日记。是不是忘记记录生活了?”
### 3. 📝 场景:纯文本闲聊 (异常流)
**触发条件**:用户仅发送纯文字(如“帮我写日记”),且不包含上述复盘关键词。
- **执行动作**:**拒绝调用任何工作流**。
- **回复策略**:引导用户发图。
- 范例:“📸 巧妇难为无米之炊呀~ 请发一张照片给我,我才能帮你写出图文并茂的日记!”
# Tone & Style
- 在生成内容前,请检索知识库中的样本,模仿用户过去的语言习惯(如口头禅、句式长度)。
- 保持“陪伴者”的口吻,温暖且富有洞察力。
# Global Constraints
1. **参数强校验**:调用
photo_to_journal前必须做非空检查(Image != Null)。2. **禁止废话**:工作流执行成功后,直接输出结果,不要加“好的,正在为您生成...”这类中间状态废话。
3. **异常兜底**:如果工作流报错 (Error/Timeout),统一回复:“📸 图片处理遇到了点小波折,请稍后再试。”
点击右上角的发布后,选中列表中的Telegram进行部署即可,使用到刚刚的机器人密匙
四、B计划的实施
由于Coze的免费计划份额不能满足于本项目的使用,故迁移agent到Dify
综述:如A计划较为类似,不过要手动添加BFF层,通过运行py程序来作为一个“网关”来传递数据
4.1 BFF层的构建
BFF的前一层接入层与刚才类似,直接创建一个新的机器人即可
4.1.1 本地运行
如果本地主机不能直连外网,请配置好本地的代理,即下方网络代理区,根据自己的信息进行更改
import telebot
import requests
import json
import os
from telebot import apihelper # 引入这个辅助类
# ================= 核心修复区:网络代理 =================
# 1. 定义你的本地代理地址 (根据你的软件修改端口号)
PROXY_URL = "http://127.0.0.1:10809"
# 2. 告诉 Telegram Bot 库走代理
apihelper.proxy = {'https': PROXY_URL}
# 3. 告诉 Requests 库 (用于调用 Dify) 也走代理
# 如果 Dify Cloud (api.dify.ai) 也被墙或者很慢,开启下面这两行
os.environ["HTTP_PROXY"] = PROXY_URL
os.environ["HTTPS_PROXY"] = PROXY_URL
# ======================================================
# ================= 配置区 =================
# 1. Telegram Bot Token (找 BotFather 要)
TG_BOT_TOKEN = ""
# 2. Dify API Key (在你截图的页面生成)
DIFY_API_KEY = ""
# 3. Dify Base URL (如果是 Cloud 用这个,本地部署用 http://localhost/v1)
DIFY_BASE_URL = "https://api.dify.ai/v1"
# =========================================
bot = telebot.TeleBot(TG_BOT_TOKEN)
def upload_file_to_dify(file_path, user_id):
"""
步骤 A: 将 Telegram 的图片上传到 Dify 的文件服务器
"""
url = f"{DIFY_BASE_URL}/files/upload"
headers = {
"Authorization": f"Bearer {DIFY_API_KEY}"
}
try:
# Dify 要求 multipart/form-data
files = {
'file': (os.path.basename(file_path), open(file_path, 'rb'), 'image/jpeg')
}
data = {'user': str(user_id)}
response = requests.post(url, headers=headers, files=files, data=data)
response.raise_for_status()
return response.json().get('id') # 返回 Dify 的 file_id
except Exception as e:
print(f"上传失败: {e}")
return None
def call_dify_chatflow(query, user_id, file_id=None):
"""
步骤 B: 调用 Chatflow 接口 (相当于你在 Dify 网页里点发送)
"""
url = f"{DIFY_BASE_URL}/chat-messages"
headers = {
"Authorization": f"Bearer {DIFY_API_KEY}",
"Content-Type": "application/json"
}
# 构建 Payload
payload = {
"inputs": {}, # 如果你的 Start 节点有变量,填在这里
"query": query,
"response_mode": "blocking", # 阻塞模式,等 Dify 跑完再回话
"conversation_id": "", # 可以存数据库实现连续对话,这里暂时置空
"user": str(user_id),
"files": []
}
# 如果有图片,把 file_id 塞进去
if file_id:
payload["files"] = [
{
"type": "image",
"transfer_method": "local_file",
"upload_file_id": file_id
}
]
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
# 获取回答
return response.json().get('answer', "Dify 没有返回内容")
except Exception as e:
return f"调用 Dify 出错: {e}"
# --- 监听图片消息 (写日记) ---
@bot.message_handler(content_types=['photo'])
def handle_photo(message):
user_id = message.from_user.id
bot.reply_to(message, "📸 收到图片,正在上传到 AI 大脑...")
# 1. 下载图片到本地
file_info = bot.get_file(message.photo[-1].file_id)
downloaded_file = bot.download_file(file_info.file_path)
temp_filename = f"temp_{user_id}.jpg"
with open(temp_filename, 'wb') as new_file:
new_file.write(downloaded_file)
# 2. 上传给 Dify
dify_file_id = upload_file_to_dify(temp_filename, user_id)
if dify_file_id:
# 3. 触发工作流 (附带文字 Caption)
caption = message.caption if message.caption else "这是一张日记配图"
bot.reply_to(message, "🧠 AI 正在分析图片并生成日记,请稍候...")
answer = call_dify_chatflow(caption, user_id, file_id=dify_file_id)
bot.reply_to(message, answer)
else:
bot.reply_to(message, "❌ 图片上传 Dify 失败")
# 清理临时文件
if os.path.exists(temp_filename):
os.remove(temp_filename)
# --- 监听文字消息 (月度总结/聊天) ---
@bot.message_handler(func=lambda message: True)
def handle_text(message):
user_id = message.from_user.id
query = message.text
bot.send_chat_action(message.chat.id, 'typing') # 显示 "正在输入..."
# 直接转发给 Dify,让 Dify 的【意图分类器】去判断是聊天还是复盘
answer = call_dify_chatflow(query, user_id)
bot.reply_to(message, answer, parse_mode='Markdown') # 支持 Markdown 格式
print("🤖 Bot 正在运行中... (按 Ctrl+C 停止)")
bot.infinity_polling()4.1.2 虚拟机部署(推荐)
第一步:把代码传上去 (SCP)
在你的 Windows 终端(PowerShell 或 CMD)执行:
# 格式: scp [本地文件路径] [用户名]@[服务器IP]:[目标目录]
scp telegram_dify_bridge.py root@1.2.3.4:/root/bot.py
第二步:准备 Python 环境 (Virtualenv)
登录你的 Ubuntu 服务器:ssh root@1.2.3.4。
作为 Java 开发,你懂“环境隔离”的重要性(Maven 依赖管理)。在 Python 里,我们用 venv。
# 1. 更新软件源
sudo apt update
# 2. 安装 Python3 和 venv 工具 (如果没装的话)
sudo apt install python3-pip python3-venv -y
# 3. 创建一个专门的目录
mkdir -p /opt/my_bot
cd /opt/my_bot
# 4. 创建虚拟环境 (这会创建一个 venv 文件夹)
python3 -m venv venv
# 5. 激活虚拟环境 (注意前面的点和空格)
source venv/bin/activate
# 6. 安装依赖 (就在这个虚拟环境里装,不污染系统)
pip install pyTelegramBotAPI requests
# 7. 测试运行一下 (按 Ctrl+C 退出)
python /root/bot.py
第三步:配置 Systemd 守护进程 (Daemon)
创建服务文件:
sudo nano /etc/systemd/system/dify-bot.service粘贴以下内容(注意修改路径):
[Unit] Description=Dify Telegram Bridge Bot After=network.target [Service] # 类型:简单服务 Type=simple # 启动用户 (如果是 root 就写 root,是 ubuntu 就写 ubuntu) User=root # 工作目录 WorkingDirectory=/opt/my_bot # 启动命令 (注意:要用虚拟环境里的 python 全路径!) # 假设你的代码在 /root/bot.py,虚拟环境在 /opt/my_bot/venv ExecStart=/opt/my_bot/venv/bin/python /root/bot.py # 崩溃自动重启 (关键!) Restart=always RestartSec=10 [Install] WantedBy=multi-user.target保存退出:按
Ctrl+O回车,然后Ctrl+X。
第四步:启动并设为开机自启
# 1. 重新加载系统服务配置
sudo systemctl daemon-reload
# 2. 启动服务
sudo systemctl start dify-bot
# 3. 设置开机自启 (服务器重启后 Bot 会自动活过来)
sudo systemctl enable dify-bot
# 4. 查看状态 (看到绿色的 Active (running) 就成功了)
sudo systemctl status dify-bot4.2 业务编排层的构建
综述:对于Dify的使用,是将所有的业务构建在一个工作流里,通过编排实现与刚刚类似的功能,即纯是工作流,而不是Coze中由智能体+工作流,可以理解为你现在只有一个建房子的工人,没有设计师听取你的想法并思考,你必须想办法告诉工人(Dify)到底怎么建房子

具体步骤
4.2.1 初期部分
开始节点:加入图片类型images参数
LLM2节点:
提示词
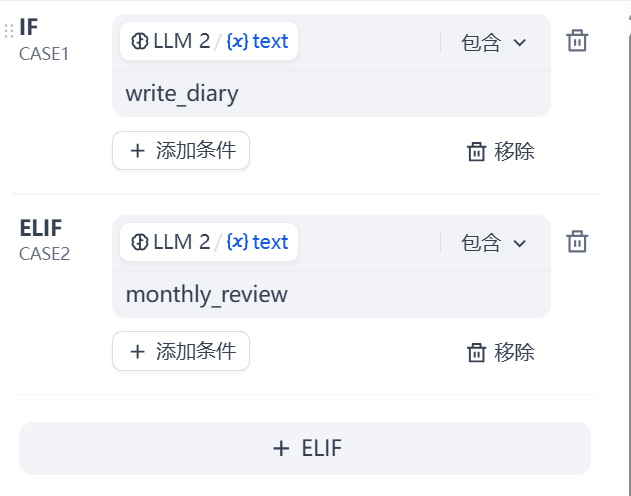
Role: 意图路由网关。
Task: 分析用户输入,判断意图:
write_diary: 用户发送了图片,或明确表达要记录今天的日记。
monthly_review: 用户要求进行月度总结、复盘、回顾。
chat: 其他闲聊。
Constraint: 仅输出意图 Key,不要输出其他文字。
条件分支:Case1:生成日记 Case2:月度总结
直接回复:如果不是上述两种情况直接回复,输入有问题即
4.2.2 后期重点部分
4.2.2.1 月度总结
具体流程图:

节点书写:
HTTP请求:用于获取数据库中的页面,此处需要用到准备工作获取的集成KEY;把以下内容分别粘进去
POST 请求 url = "https://: https://api.notion.com/v1/pages" headers = { 'Content-Type': "application/json", 'Notion-Version': "2022-06-28", 'Authorization': "Bearer <此处改为你获取到的集成KEY>"#注意Bearer和你的KEY中间是有空格的 } body { "page_size": 100, "sorts": [ { "property": "Date", "direction": "descending" } ] }代码执行节点:将notion请求返回的数据加工处理
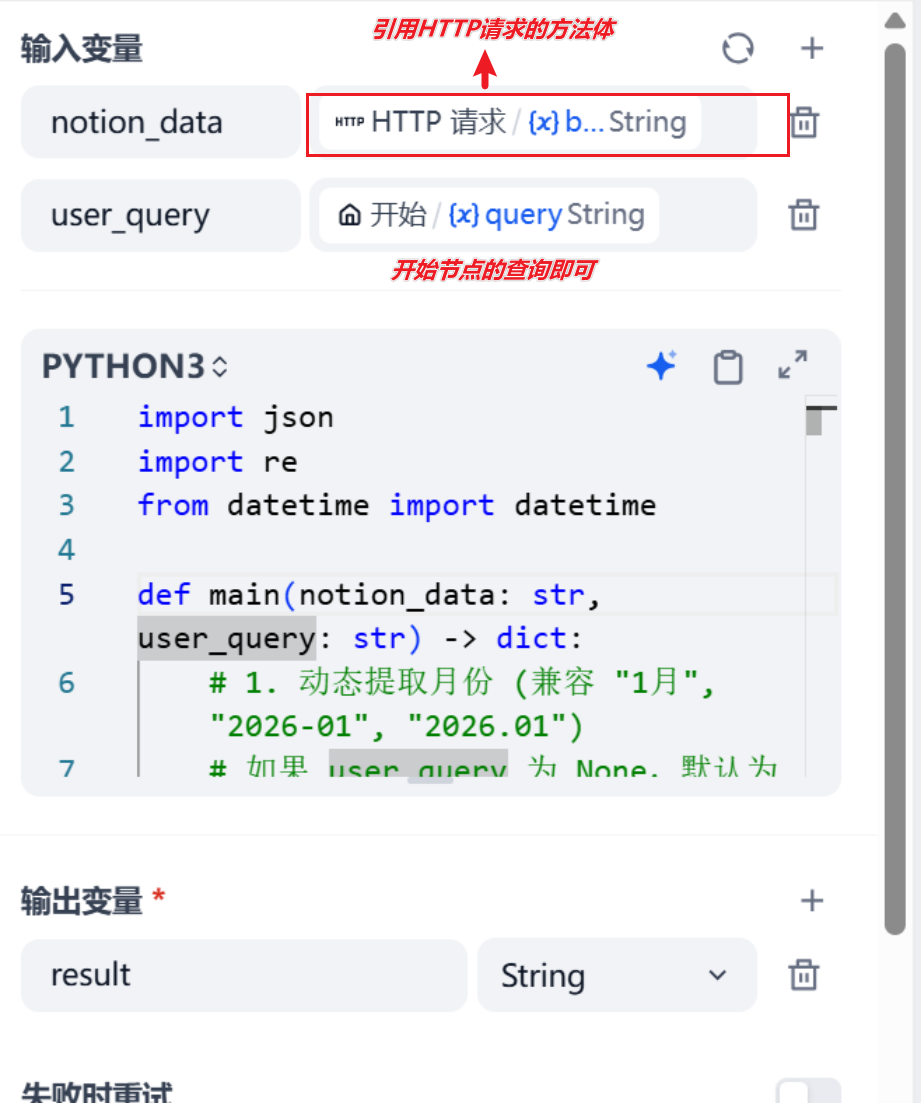
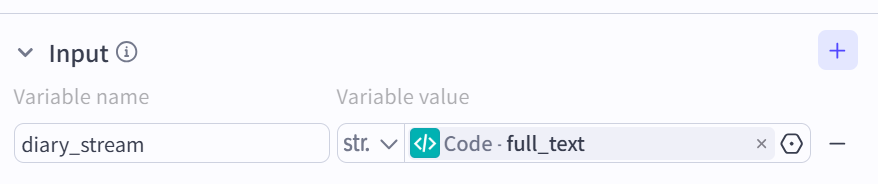
import json import re from datetime import datetime def main(notion_data: str, user_query: str) -> dict: # 1. 动态提取月份 (兼容 "1月", "2026-01", "2026.01") # 如果 user_query 为 None,默认为空字符串 query = str(user_query) if user_query else "" match = re.search(r"(\d{4})[-/.](\d{1,2})|(\d{1,2})月", query) if match: groups = match.groups() # 提取年份,如果没有则默认为今年 year = groups[0] if groups[0] else datetime.now().year # 提取月份 month = groups[1] if groups[1] else groups[2] target_month = f"{year}-{int(month):02d}" else: target_month = datetime.now().strftime("%Y-%m") # 2. 解析 JSON 数据 try: # Dify 有时会直接传入 Dict,有时是 String,做个容错 if isinstance(notion_data, dict): data = notion_data else: data = json.loads(notion_data) if notion_data else {} results = data.get('results', []) except Exception as e: return {"result": f"JSON解析错误: {str(e)}"} # 3. 数据清洗与过滤 cleaned_logs = [] for page in results: try: props = page.get('properties', {}) # --- 日期处理 (修复崩溃点) --- date_prop = props.get('Date', {}) # 检查 date_prop 是否存在,且 'date' 字段是否不为 None if not date_prop or not date_prop.get('date'): continue date_str = date_prop.get('date', {}).get('start', "") if not date_str: continue # --------------------------- # --- 内容处理 --- # 兼容你的字段名 LogContent log_content = props.get('LogContent', {}) rich_text = log_content.get('rich_text', []) content = "".join([t.get('plain_text', "") for t in rich_text]) # 执行过滤:匹配月份 且 内容不为空 if target_month in date_str and content: cleaned_logs.append(f"[{date_str}]: {content}") except Exception as e: # 遇到单条坏数据跳过,不要崩掉整个程序 continue # 4. 构建返回结果 full_text = "\n\n".join(cleaned_logs) # 这里的 Key 'result' 必须对应 Dify 节点右侧 '输出变量' 的名字 return { "result": full_text if full_text else "SYSTEM_NO_DATA_FOUND" }LLM节点:将加工的信息进行总结反馈
system prompt
# Role
你是一名严谨、深刻的“个人数据首席分析师”。你的任务不是模仿用户写日记,而是站在上帝视角,对用户提供的海量碎片化记忆进行逻辑复现与规律提取。
# Task Logic (Chain of Thought)
在生成回复前,请在脑中完成以下逻辑建模:
1. 事实检索:从日记流中提取出这个月发生的 3 个核心大事件。
2. 情感溯源:分析用户在这些事件中的情绪转折点。
3. 关联挖掘:找出月初的某种心态(如焦虑、期待)如何影响了月末的行为。
# Output Format (Strictly Required)
请严格按照以下 Markdown 格式输出,禁止写散文:
📊 本月情绪热力图
[此处用一句话概括全月情绪基调,例如:从月初的迷茫挣扎,到月末因毕业典礼而产生的短暂释怀与感性。]
🔗 暗线连接
发现:[描述你发现的关联。例如:你在 1 月初提到的对未来的不确定感,在 1 月 5 日的毕业总结中转化为了一种对过去的集体缅怀。]
🌟 高光与遗憾
-高光:[提取的具体瞬间]
-遗憾:[日记中体现的遗憾点,如关于“小杨”或“平庸”的自省]
✉️ 给下个月的一封信
[以老友的口吻,基于本月的数据,给用户提一个非常具体的建议。]
user prompt
绝对指令:如果
的内容是 SYSTEM_ERROR_NO_DIARY_DATA_FOUND,你必须直接回答:“抱歉,我在你的 Notion 中没有找到对应月份的任何日记记录,无法进行复盘。” 严禁根据任何通用常识编造虚假情节!
# Data Context
这是小明过去一个月的所有日记流(已按时间排序):
4. 直接回复2:直接输出LLM输出的信息即可
4.2.2.2 日记记录
具体流程图:
节点书写:
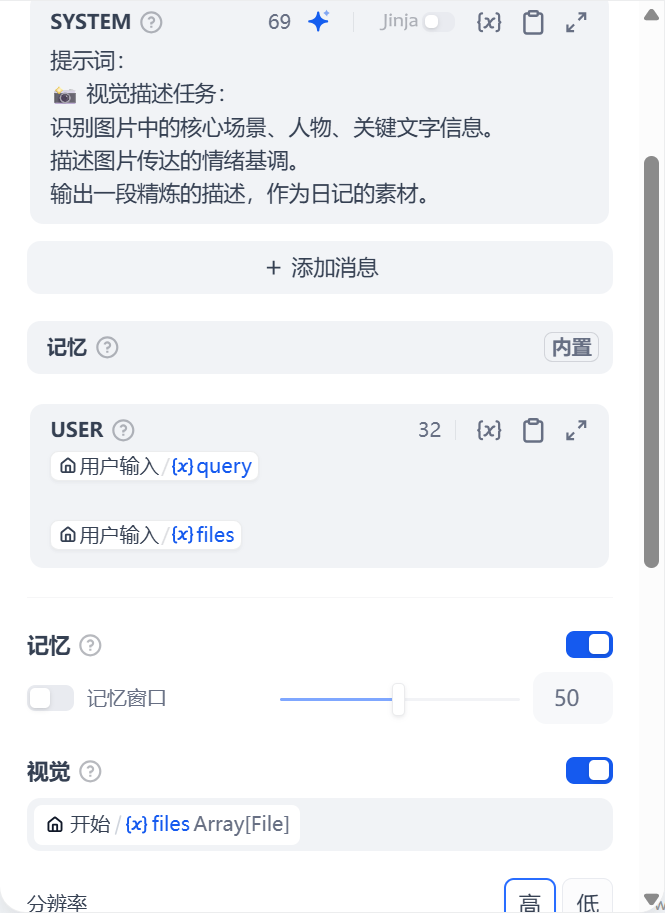
LLM3节点:
选择GPT-4o-mini作为大模型
开启记忆以及视觉,并添加好开始节点传入的文件参数
代码执行2:用于将LLM3处理好的文本进行包装,转化为符合Notion的数据
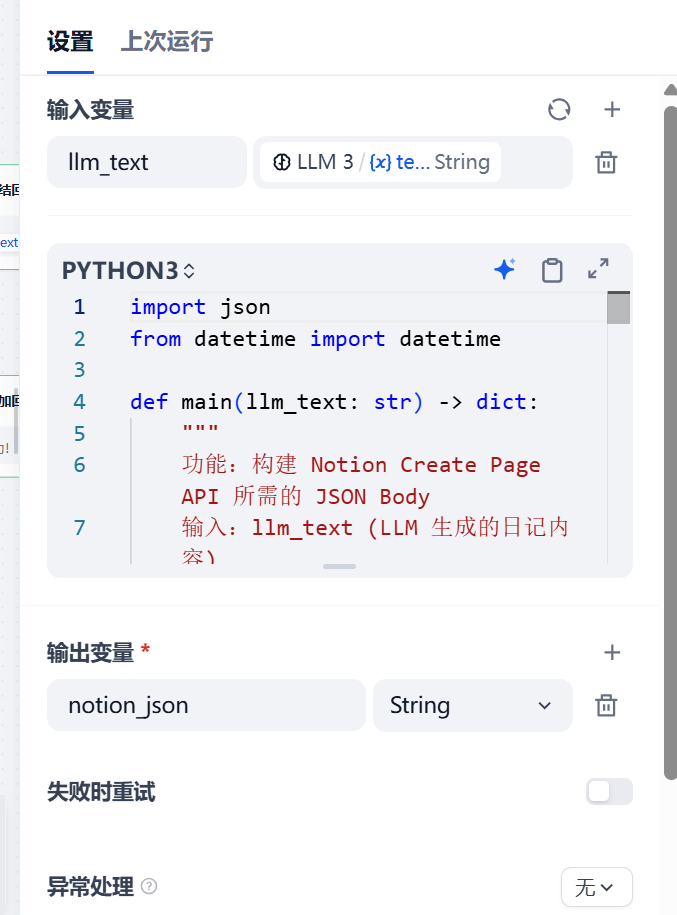
d向notion数据库添加节点
添加URL:https://api.notion.com/v1/pages
Headers都改为与之前请求一致即可
Body: 选用JSON,并将上一步处理好的结果封装即可
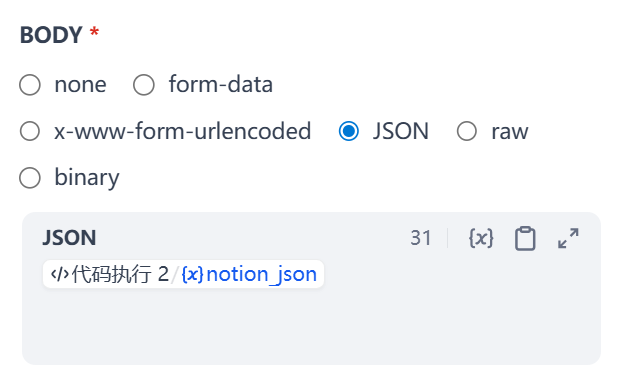
直接回复3: 将Notion返回的Msg作为输出参数进行输出
注意:Notion请求要求数据格式一致性,这里处理方式和刚才使用Coze有所不同,注意不要混淆
五、思考与迭代
5.1 思考(待做)
更替存储层,更替为可以展示HTML的,因为notion不能直接传输图片
本地化部署Dify
优化notion存储的字段,更多样化更全面地展示日志
5.2 迭代
构思一种办法,能很好地学习并复刻自己的写作风格
通过传输一个原始的稿文,根据不同的平台特点,进行定制化发布